Buying Happiness
Using Word2Vec to Turn Feelings Into Trades

Max Margenot
Lead Data Scientist at Quantopian
This presentation is for informational purposes only and does not constitute an offer to sell, a solicitation to buy, or a recommendation for any security; nor does it constitute an offer to provide investment advisory or other services by Quantopian, Inc. ("Quantopian"). Nothing contained herein constitutes investment advice or offers any opinion with respect to the suitability of any security, and any views expressed herein should not be taken as advice to buy, sell, or hold any security or as an endorsement of any security or company. In preparing the information contained herein, Quantopian, Inc. has not taken into account the investment needs, objectives, and financial circumstances of any particular investor. Any views expressed and data illustrated herein were prepared based upon information, believed to be reliable, available to Quantopian, Inc. at the time of publication. Quantopian makes no guarantees as to their accuracy or completeness. All information is subject to change and may quickly become unreliable for various reasons, including changes in market conditions or economic circumstances.
Background¶
- Me
Unstructured Data¶
Key source of "alpha"
Natural Language Processing (NLP)¶
Computer science and linguistics tools to interpret human language and text
Allows us to quantify unstructured text
Data Processing¶
- Stopwords
- Stemming
- Tokenization
Feature Generation¶
Bag of Words¶
Unigrams¶
my_phrases = ['Show me the alpha', 'Carthago delenda est',]
[phrase.split(' ') for phrase in my_phrases]
Bigrams¶
[word for phrase
in my_phrases for word
in zip(phrase.split(' ')[:-1], phrase.split(' ')[1:])]
print(w2v.wv['sad'])
w2v.wv.most_similar('sad')
plot_embedded_clusters(dim_red, clustered_wv_df.labels_, legend=[1, 8, 12, 32])

wv_df[clustered_wv_df.labels_ == 1].head()
The Data¶
Sentiment140¶
Twitter sentiment dataset
My Approach¶
Logistic Regression with Bag of Words
Neural Network with Word Embeddings
Logistic Regression¶
\begin{eqnarray} g(X) &=& \alpha + \beta_0 X_0 + \cdots + \beta_n X_N \\ F(X) &=& \frac{1}{1 + e^{-g(X)}} \end{eqnarray}
Friendly, familiar linear model
Easy to interpret and understand
Logistic Regression Coefficients¶

Results¶


Neural Networks¶
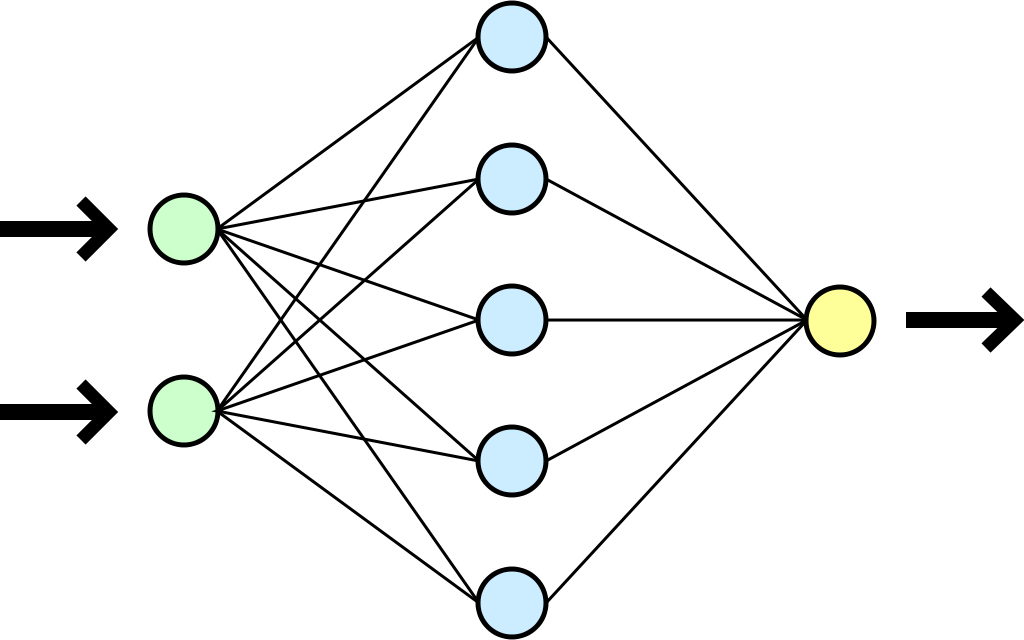
Neural Networks¶
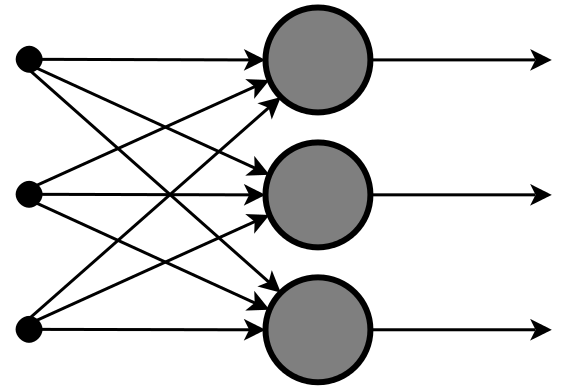
Recurrent Neural Networks¶
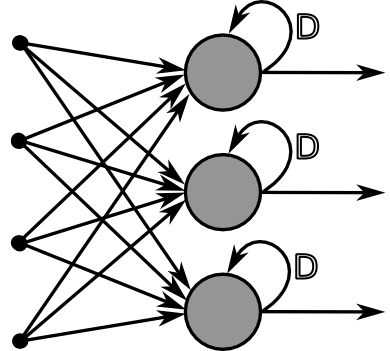
Recurrent Neural Networks¶
Recurrent neural networks good for text processing
View sentences as sequences of words (similar to time series structure)
Long Short-term Memory Networks¶

Long Short-term Memory Networks¶
In Keras this is simple to implement
input_layer = Input(shape=(MAX_WORDS,))
embedding_layer = Embedding(max_features+1,
embedding_dim,
input_length=MAX_WORDS)(input_layer)
lstm_layer = LSTM(64,
dropout=DROPOUT,
activation='tanh',
return_sequences=True)(embedding_layer)
lstm_layer = LSTM(128,
dropout=DROPOUT,
activation='tanh')(lstm_layer)
output = Dense(1,
activation='sigmoid',
name='sentiment')(lstm_layer)
Results¶


How to Compute A Signal?¶
Hypothesis: POTUS's tweets affect the market
Precedent¶
- Trump2Cash: https://github.com/maxbbraun/trump2cash
- Waits for the president to mention publicly-traded companies
- Uses sentiment analysis to determine positivity or negativity
- Enters long or short positions based on sentiment
- BOTUS: https://twitter.com/botus
- Waits for the president to mention publicly-traded companies
- Uses sentiment analysis to determine positivity or negativity
- Enters long or short positions based on sentiment
- Trump & Dump: https://www.t-3.com/work/the-trump-and-dump-bot-analyze-tweets-short-stocks-save-puppies-all-in-seconds
- Waits for the president to mention publicly-traded companies
- Uses sentiment analysis to determine positivity or negativity
- Enters short positions based if sentiment is negative
Factor Models¶
CAPM
$$ r_p = \alpha + \beta_{m} r_{m} $$
Fama-French Factors
$$ r_p = \alpha + \beta_{m} r_{m} + \beta_{hml} r_{hml} + \beta_{smb} r_{smb} $$
Alternative Factors
$$ r_p = \alpha + \beta_0 r_0 + \cdots + \beta_n r_n $$
Risk Modeling¶
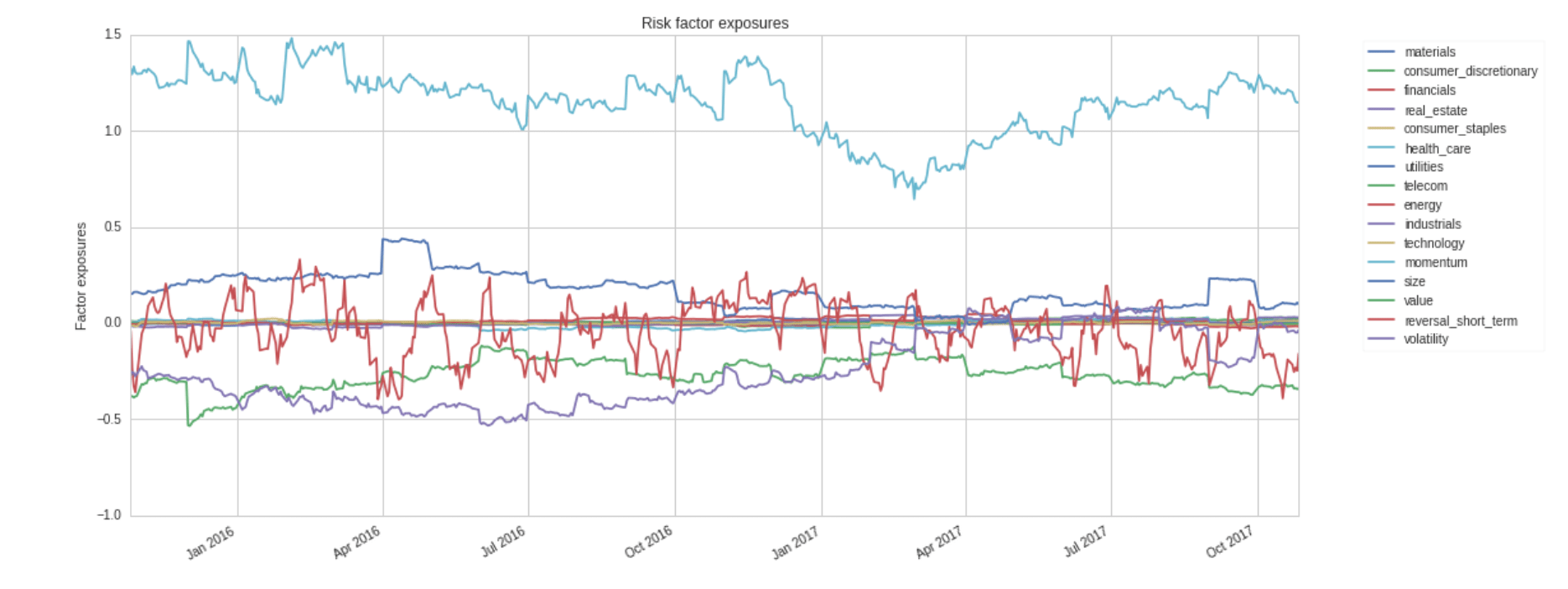
Cross-sectional Equity Portfolios¶
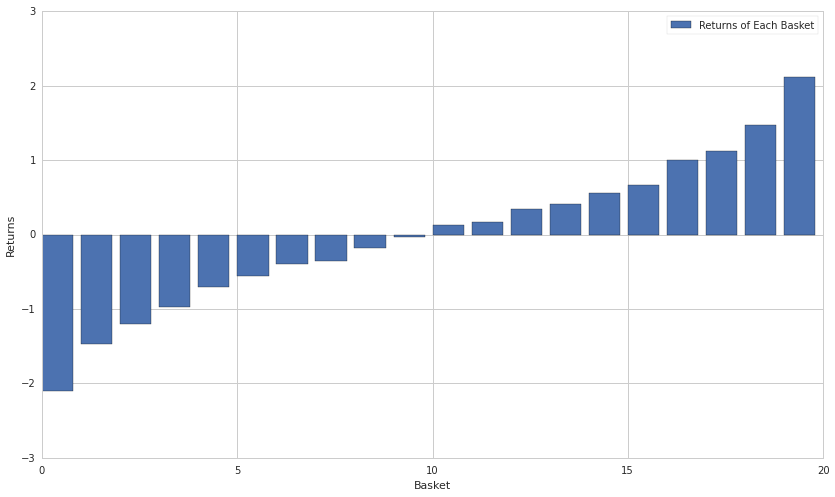
Average Sentiment Each Day¶
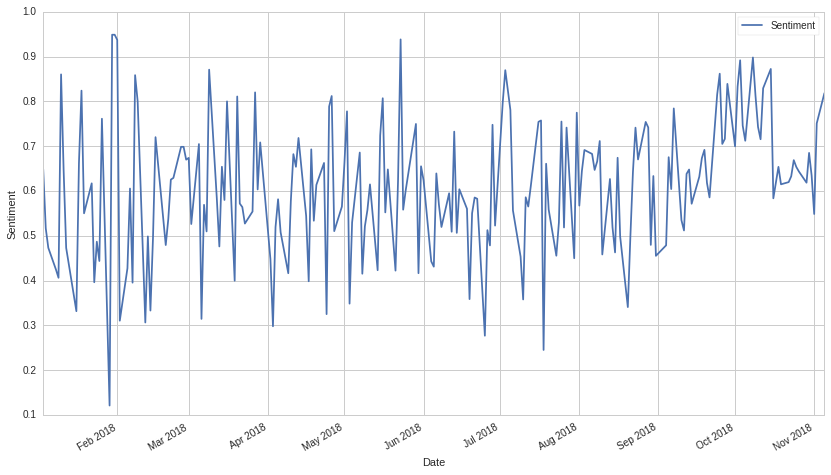
Sentiment Exposure Signal¶
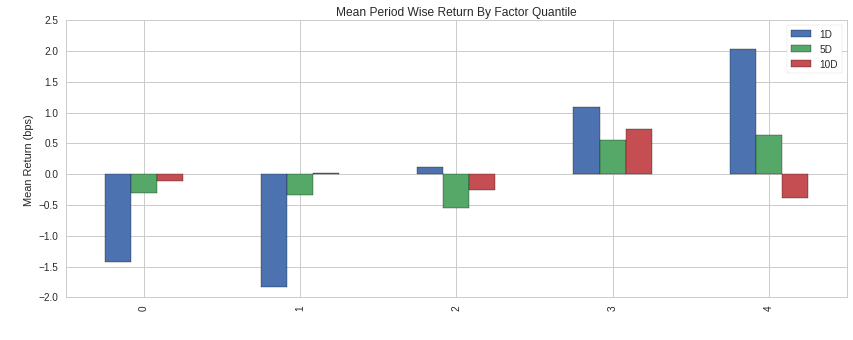
Sentiment Exposure Signal¶
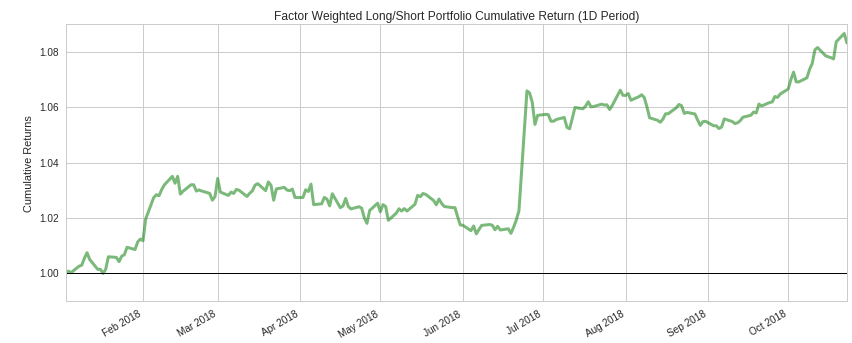
Sentiment Exposure Signal¶
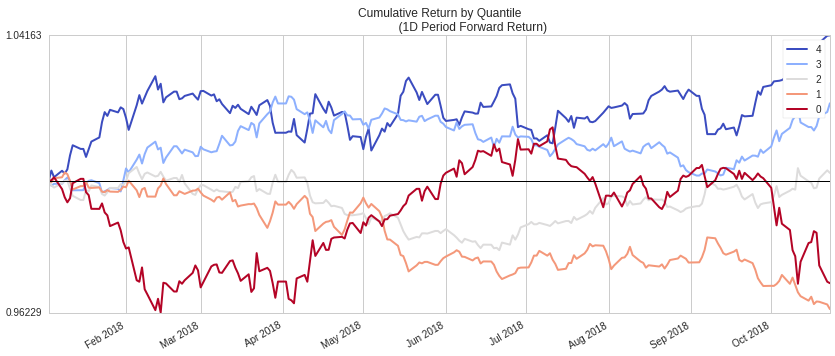
Performance Attribution¶
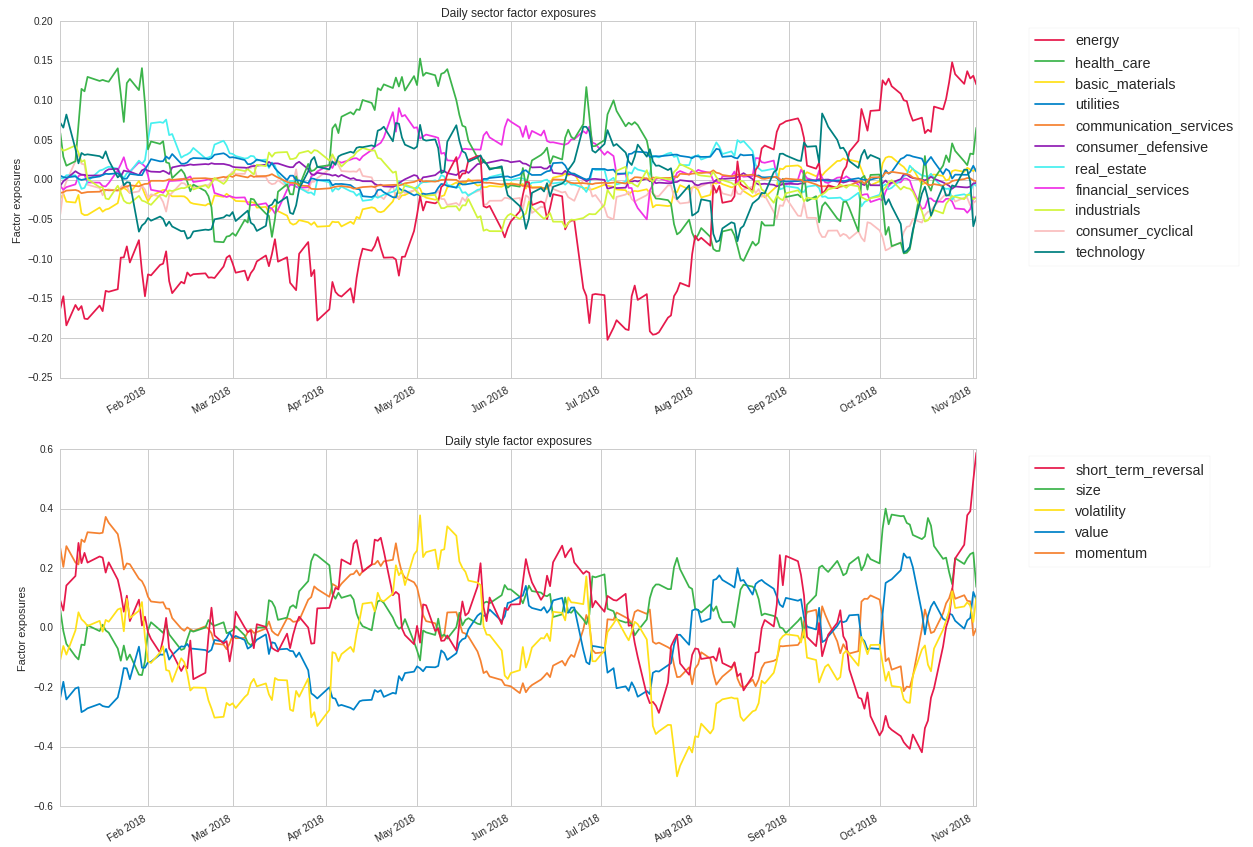
Performance Attribution¶
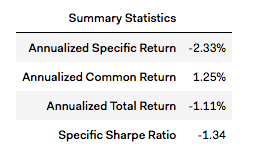
Performance Attribution¶
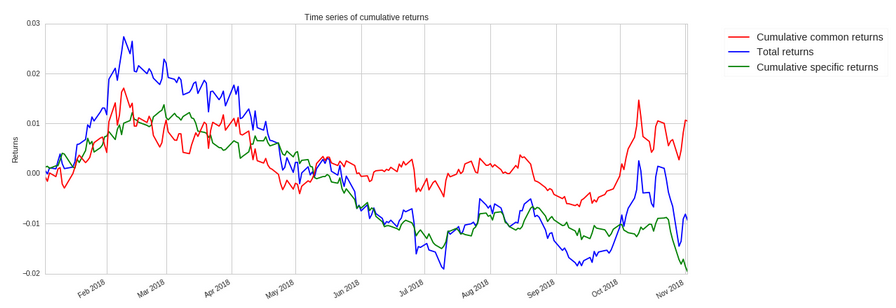
Tools¶
- Natural Language Toolkit (NLTK): http://www.nltk.org/
- scikit-learn: https://github.com/scikit-learn/scikit-learn
- Gensim: https://github.com/RaRe-Technologies/gensim
- Keras: https://github.com/fchollet/keras
- Alphalens: https://github.com/quantopian/alphalens
- Pyfolio: https://github.com/quantopian/pyfolio
- Quantopian Lecture Series: https://quantopian.com/lectures
- Quantopian Research: https://quantopian.com/research
References¶
- Go, A., Bhayani, R. and Huang, L., 2009. Twitter sentiment classification using distant supervision. CS224N Project Report, Stanford, 1(2009), p.12.
@clean_utensils
@mmargenot
max@quantopian.com
This presentation is for informational purposes only and does not constitute an offer to sell, a solicitation to buy, or a recommendation for any security; nor does it constitute an offer to provide investment advisory or other services by Quantopian, Inc. ("Quantopian"). Nothing contained herein constitutes investment advice or offers any opinion with respect to the suitability of any security, and any views expressed herein should not be taken as advice to buy, sell, or hold any security or as an endorsement of any security or company. In preparing the information contained herein, Quantopian, Inc. has not taken into account the investment needs, objectives, and financial circumstances of any particular investor. Any views expressed and data illustrated herein were prepared based upon information, believed to be reliable, available to Quantopian, Inc. at the time of publication. Quantopian makes no guarantees as to their accuracy or completeness. All information is subject to change and may quickly become unreliable for various reasons, including changes in market conditions or economic circumstances.